以《数字音频基础》书中章节为纲要的笔记与问题集。知识内容并不以此书为标准而是综合研究了多本专业书目。
第一章 MIDI基本理论
问题集
1,什么叫做MIDI?
【基本含义】Musical Instruments Digital Interface 的缩写,音乐设备数字界面或乐器数字接口,它是数字音乐设备之间的一套通信协议。
【完整概念】
a. 硬件连接 —— MIDI规定了硬件接口标准:最早的5芯标准MIDI接口和线缆,最多16个硬件通道;
b. 信息格式 —— MIDI协议是MIDI技术的关键,因为它规定了以何种格式进行数据传输。
c. 标准MIDI文件存储 —— 它使MIDI的概念扩展完整,并使MIDI作为大众传播媒介成为可能。MIDI文件两个基本特征:同一文件在不同播放载体上结果不同,因各自合成器音色不同;最终听到的音乐质量取决于MIDI文件内的音乐编辑质量。
通过MIDI线连接演奏信息的发送和接收端,当演奏信息通过MIDI端口被送出后,由音序器记录MIDI数据,即“录制MIDI”。记录下来的MIDI数据能够进行自由编辑,这是MIDI极为重要并具有划时代意义的一大特点。MIDI接口和音序软件的出现实现了MIDI接口与电脑的连接,实现了音序软件在电脑上的使用,也实现了演奏信息在电脑上的记录、编辑和播放,从而开创了专业的电脑音乐制作系统。
“接口 interface”指的是,在一个搭建好的MIDI系统中的实际数据传输连接以及软硬件系统。通过使用MIDI技术对实时演奏信息和对MIDI控制数据的传输,可以将数据定位至系统内的每一个电子乐器和控制设备上。这种数据传输主要通过一种单向传输的电缆实现。(该电缆可实现级联 —— 把两个以上的设备通过某种方式连接起来,起到扩容效果的就是级联)
这种电缆可同时传输16个独立通道的演奏和控制信息。由此,电子音乐家们可以在一个模仿多轨录音的工作环境中录制、加录、编辑、回放他们的演奏,其性能远超传统的磁带多轨录音,使音乐制作有了更多的可能性。
2,最常见的MIDI标准
【常见的】
-
GM(General MIDI System Level 1 or GM 1,通用MIDI 1.0 规范化标准)
最常见的标准,它制定了一些至今仍广泛使用的规则,如MIDI通道10为打击乐专用通道;每个音色库最大包含128个音色;控制码组总共128个控制码等。 -
DLS(downladable sounds)
可载入音色的MIDI,DLS文件允许MIDI文件携带音色样本。 -
GS(Roland General Standard MIDI)
Roland公司制定的标准MIDI规格,扩展了新的MIDI表现控制功能,支持MIDI标准文件,兼容GM音源模块。GS编号为1-128(GM编号为0-127)。
【其他】
-
GM2
在GM1基础上的扩展,增加了更多音色和控制,GM2设备都兼容GM1标准。GM2并不普遍。 -
XG(Extended General MIDI)
扩展GM标准,由Yamaha制定。
3,简述MIDI标准的发展历程
1983年诞生了MIDI规范1.0,随着技术的发展完善,1995年确立了GM1,解决了兼容性问题。
随着技术进步和需求增长,出现了GM2,但并未成为普遍标准。
1997年出现了DLS,使得MIDI标准文件可携带音色样本。
XG在90年代中期诞生,未成为普遍标准。
Roland公司也制定了扩展标准——GS,如今大部分电脑上GM与GS并存。
4,画出基本的基于电脑软件音序器的MIDI系统构成图
+-----------------+
| MIDI 控制器 |
+--------+--------+
| MIDI 连接(MIDI IN)
|
+--------v--------+
| 音序器软件 |
+--------+--------+
| MIDI 连接(MIDI OUT)
|
+--------v--------+
| 音频接口设备 |
+-----------------+
| 音频连接(Line Out)
|
+--------v--------+
| 扬声器/耳机 |
+-----------------+在这个系统中,MIDI 控制器通过 MIDI 连接(通常是 MIDI 电缆)将 MIDI 数据传输到音序器软件。MIDI 控制器充当输入设备,用户可以使用它们来演奏乐器、调整参数等。
音序器软件接收来自 MIDI 控制器的 MIDI 数据,并根据数据指令生成相应的音频信号或控制信息。音序器软件通过 MIDI 连接将生成的 MIDI 数据发送回 MIDI 控制器(MIDI OUT),以便一些控制器上的显示屏或 LED 指示灯能够反馈相关信息给用户。
音序器软件也可以通过音频连接将生成的音频信号发送到连接在计算机上的音频接口设备。音频接口设备负责将数字音频信号转换为模拟信号,并通过线缆连接将其输出到扬声器、耳机或其他外部音频设备中。用户可以通过扬声器或耳机听到生成的声音。
5,USB或火线端口可以直接用来传输MIDI信号吗?
可以,USB或IEEE1394可以将电脑与MIDI设备连接进行双向交流,且带来更高精度的MIDI信号,并能同时传输数字音频信号。
6,判断:标准MIDI通道的数量没有限制。
错。MIDI标准规定了最大16个通道,无论是物理通道还是在软件端。
7, MIDI连接是否既可以采用并联也可以采用串联?(MIDI典型配置)
对于 MIDI 设备的连接,通常采用daisy-chain的方式(算是某种串联)。这意味着将 MIDI 输出端口连接到下一个设备的 MIDI 输入端口,如此类推,以形成一个连续的链条。
每个 MIDI 设备都有一个 MIDI 输入端口和一个 MIDI 输出端口。通过将输出端口与下一个设备的输入端口相连,可以将多个设备链接在一起,形成一个 MIDI 网络。最后一个设备的输出端口可以连接到计算机或其他接收 MIDI 信号的设备。
并联(parallel)连接不太常见,在传统的 MIDI 接口中并不支持。然而,现代的 USB MIDI 接口提供了更多的灵活性,允许多个设备同时连接到计算机上的 USB 端口。
总之,大多数情况下,MIDI 设备之间的连接采用daisy-chain的方式,Thru直通口为多设备级联提供了可能。
Daisy Chain
The simplest connection topology is the daisy chain, where one transmitter is connected to one or more receivers.
In this example, the MIDI out of a controller is connected to the MIDI in of a tone generator module. It allows the player to use the keys on the controller to play sounds from the module. The controller sends note-on, note-off and controller messages, to be interpreted into sound by the module. The communication path is unidirectional.If the module is multitimbral, it can be set to respond on several MIDI channels, allowing the player to switch between sounds by changing the transmission channel.
We can add more downstream modules using the thru ports on the interceding devices. Thru transmits a copy of the messages received by the in port.
Depending on how the controller and modules are configured, there are several possibilities.
The modules could simply all respond together, in unison.
Each module could be set to respond on a different MIDI channel. By changing the channel that the controller sends, the modules can be played individually.
Each module could be configured to respond to particular key or velocity ranges, forming splits and layers.
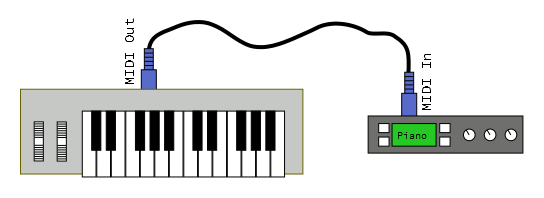
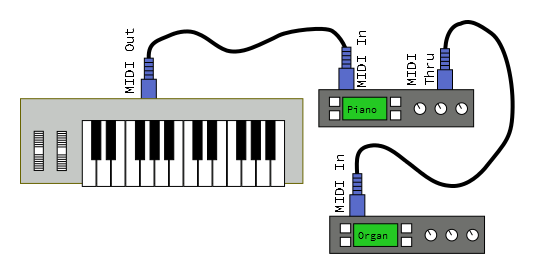
https://learn.sparkfun.com/tutorials/midi-tutorial/topologies
- 级联
从源设备传输数据到另一个设备的MIDI in端口,此时正在传送的数据可以被复制并由MIDI Thru/Out送出,MIDI链中的下一个设备可以同样的方式继续向下传输。(MIDI Thru 端口是用来复制传入的 MIDI 数据,并将其发送到下一个设备的端口。这样,每个设备都可以同时接收到原始数据,并将其传递给下一个设备。这种方式允许在 MIDI 链中同时控制多个设备,而无需使用额外的分配器或其他设备来复制和分发 MIDI 数据。)
8,判断:现在可以不需要标准MIDI协议即可进行MIDI系统连接和工作。
错。所有MIDI设备都是建立在标准MIDI协议上的。USB和火线接口的MIDI信息传输也是在标准协议基础上改良而来。没有标准 MIDI 协议,就无法进行 MIDI 系统连接和工作。
9,判断:标准MIDI信号必须采用5芯端口才能连接吗?
错。MIDI信号传输现在支持多种接口,除了标准5芯,还有HOST连接,Joystick/MIDI端口、USB、IEEE394(火线)等。
10,若采用USB1.0和IEEE394连接,系统连接线长度就无限制了吗?
所有连接都有长度限制,普通线缆一般不超过五米,专业高速线缆支持更远距离,但仍有限制。
11,MIDI技术等本质是什么?
【short version】
MIDI的本质是一种数字通信语言(或通信协议、通信标准),计算机电子乐器和控制设备等数字音乐设备可以通过这种信号实现相互间的对话,从而协同工作。
【long version】
MIDI 技术的本质是通过数字消息来描述音乐事件。这些消息包含有关何时开始或停止播放一个音符、音符的音高、音量和持续时间,以及其他各种控制命令。
MIDI 消息基于二进制编码,并通过 MIDI 接口(通常使用 MIDI 电缆)在设备之间传输。每条 MIDI 消息由一个状态字节和一到两个数据字节组成。状态字节指示消息的类型(例如音符开启、控制变化等),数据字节携带与该消息相关的参数值。
MIDI 本身只传输音乐数据和控制命令,并不传输声音本身。声音的生成和播放是由接收 MIDI 消息的设备(如合成器、音源模块或计算机软件)负责完成。
MIDI 技术的优势在于其灵活性和可扩展性。它可以实现多个设备之间的实时通信,使得演奏者可以使用 MIDI 控制器来操控各种音源设备,或将它们连接到计算机上的音序器软件进行录制和编辑。
总而言之,MIDI 技术提供了一种标准化的音乐通信方式,使得不同类型的音乐设备能够互相交流和控制,为音乐创作、演奏和录制带来了很大的便利性和灵活性。
12,GM和GS的硬件复位系统码分别是什么?
GM和GS是MIDI标准,它们自己没有系统码,只是规范了系统专用信息的格式。系统专用信息是由各个设备制造商定义和使用的。
按照教科书上所提到的GS模式下的复位系统码:
GS - F0 41 10 42 12 40 00 7F 00 41 F7
F0: 起始状态字节,表示这是一个系统专用信息,41: 厂商 ID,表示罗兰(Roland),10: 设备 ID 或频道号。具体意义取决于设备。 中间是不限长度的数据信息内容。 41: 终止状态字节,表示系统专用信息的结束,F7: 结束状态字节,表示 MIDI 消息的结束。
GM - F0 E 7F 09 01 F7
13,MIDI系统码对使用者的意义
系统码,即系统专用信息System Exclusive Message 是强大的工具,也是面向用户最频繁的一些控制信息。许多控制码无法完成的复杂工作可用系统码来实现。如修改默认混响类型、音色参数调整、设备复位等。
14,如何将一台合成器中当前的设置完全保存到音序器中?
把合成器里所有音色和设置数据以SysEx转储的形式传送到音序器的转储工具或SysEx轨中;
新建一个MIDI轨,录制合成器系统专有信息(设备要开启此功能),保存文件。
也可用一些第三方软件,如SysEx Librarian,设备与电脑连接好后,开启设备SysEx传输状态,录制、保存文件。
15,简述MIDI 1和MIDI 0的区别
格式0中,所有MIDI数据都整合保存在一条MIDI轨道上;
格式1中,保留原音轨结构,分轨保存,对于编辑工作最方便,但文件会更大一些。
16,判断:鼓组音色在GM或XG中必须使用轨道10.
错。标准协议中规定了“通道10”作为鼓组音色,但通道 Channel 的概念跟音序软件中的“音轨”概念完全无关。MIDI音序软件中的音轨 track 是一个虚拟的数据存放形式,相比之下MIDI通道可说是有“物理意义”的真实数据通道。
单个MIDI线缆(或单个port)只能包含最多16个通道,但音轨作为一种编辑方式,理论上没有数量限制,很多个音轨可能走同一条MIDI通道。一个音轨也可以不设置任何通道,而是用来留存其他信息资料。
第二章 声学与心理声学
名词与概念 - 声学基础
-
声波特征
声波是一种纵波,其振荡方向与传播方向一致。根据声波的全方向辐射的特征,也称其为一种“球面波”。 -
波长
声波在一个运动周期内传播的距离。 -
频率
一秒内声波完成一个周期的次数(振动一个来回的次数),单位:赫兹 Hz。 -
振幅
声波的振动幅度(媒质位移的程度),幅度越大、声音强度越大。 -
复合波
理论上,自然界任何一种声音都可以有不同频率、振幅的正弦波叠加而成,形成“复合波” -
基频/基频波
复合波中频率最低的“基本正弦波” -
谐波
基频的整数倍频率分量。 -
基音
乐器声学中,基频又称为基音,通常是一个频率最低的音,乐音的“音高”取决于基音的频率。 -
泛音
基音以上的所有谐波。第一次泛音,对应第二次谐波,第二次泛音,对应第三次谐波,以此类推。传统声学乐器的声音特征主要取决于泛音的数量和振幅。 -
直达声
从声源发出的声波,直接送达人耳(没有经过反射)的那部分声音。 -
声波的反射
声源发出的声波在传播过程中遇到障碍物反射回来的现象。 -
漫反射
声波在传播过程中遇到各种不同的障碍物形成反射,复杂的反射面造成多角度的反射,这一现象称为漫反射。 -
混响
混响是指声音在环境中反射、散射和衰减后产生的余音效果。当声源发出声音时,声波会与周围的物体相互作用,一部分能量被吸收,而另一部分会被反射和散射回到空间中。这些反射声波与原始声音同时存在,并以稍微延迟和较低的强度继续传播,形成了混响效果。 -
衍射
声音传播过程中,遇到厚度与声波波长相等或相近的障碍物时,声音绕过障碍物,传到障碍物背后去的现象。(可闻波长 0.017~17 米) -
声波干涉
频率相同的两个声波相遇会发生叠加,造成相遇的某一些区域声音变强、另一些区域声音变弱。室内声源的直达声和反射声经常产生干涉现象。 -
相位
相位是描述波形或周期性信号的特性之一。它表示在给定时刻相对于参考点的位置或偏移量。(或者也可以说,是描述两个/多个波之间的时间关系的物理参量。)
相位可以描述一个事物与其自身的相对关系(比如颠倒或翻面),它描述了一个“相对于之前朝向的”朝向。作为波的一个真实属性,相位可被看成一个参考点与一个运动波之间的相互关系,这个参考点实际上是该波在不运动时的一个“快照”。
相位也可看成是同一个波的两个相同复本在时间上被间隔开来后,两者之间的相互关系。当两个波完美匹配时(完全重合的正负峰值和过零点),两个波就是同相的(in phase);当一个波的峰值(peak)与另一个波的峰谷(trough)在时间上刚好重合,振幅刚好抵消,就可以说这两个波是异相的(out of phase),或反转的(inverted)。
相位都是循环的,用度或弧度来衡量。 -
叠加与相位对消、干涉
两个波在某一瞬间或空间上的某一点加在一起得到一个新波,形成“叠加”。
两个频率相同的波若具有完全相同的相位,叠加时会相互加强;若两个波的相位相反,两者相加就会彼此对消。若两个波以相反方向运动并在某点相遇,则它们会彼此“干涉”。叠加与干涉是在波运动时发生的局部现象,之后两个波会沿着原本的传播方向继续运动。每个波所携带的能量是一个标量,不管方向、相位如何,每个波所含的都是一个正值的能量。波在局部彼此加强或抵消,但总能量不会消失。 -
共鸣
共鸣是声波的一个重要表现特征。共鸣,即物理学上的“共振”。两个固有频率相同的发声体靠近时,其中一个振动发声,紧接着另一个也会因共振而发声,这就形成了“共鸣”现象。 -
声场
声波存在的空间。在理想开放空间中,声音会产生一个全方向辐射的扩散声场且无反射。 -
声阻抗
声音在不同介质中传播速度不同,在流体和固体中的传播速度比在空气中的高。描述和计算这种差异的方式是运用声阻抗。在声学系统中,阻抗源自介质的黏滞力。声阻抗单位是声欧姆 $R_a$,数值上等于波阵面上声波的压强除以体积速度(介质密度与声波速度的乘积)。当一个声音在不同介质中传播时,介质的声阻抗越大,声波反射现象越显著。 -
声功率
声源每秒所发出的能量,单位:瓦特。 $1W=1J/1s$ -
声强
声强是单位面积上的声功率。单位:瓦特或者皮瓦。 -
声压
声压是单位面积上的声波压强,单位:Pa,$1 Pa=1 N/m^2$ 。波的峰值声压反比于距离。若与声源相距为r, 则峰值按 1/r 减少。声压是一个绝对量度,它施加在空间的一点上,测量时不用考虑波的方向(不同于声强这个矢量)。 -
声压级
声压级是以分贝为单位的比率,以听阈声压 20 微帕作为参考值,计算式:
$$ SPL=20\log_{10} \frac{P}{20*10^{-6}} ,\ \ \text{P为声波测量声压,以帕为单位} $$
$\diamondsuit$ 振幅的双极性 基准电平
振幅用来描述声波在空气中的压强相对于标准大气压的变化情况。传声器本质上是一种换能器,它的作用就是将空气压强变化转换为电压变化,AD转换器负责将连续的电压变化转换为不连续的码流。
与标准大气压(零参考位)相比,声波的空气压强时而高于它(形成“密部”),时而低于它(形成“疏部”),这就使得声音的振幅具有“双极性” —— 数值有正有负,因此描述声音信号的电压和数码在数值上同样是双极性的。
专业音频设备承载电压范围一般是 $-1.23V~+1.23V$,音序器软件一般使用 $-1~+1$ 的有理数范围。但用电压和小数表示信号大小非常不方便,使用分贝可以解决这一问题。
一个系统的基准电平(或标准工作电平)记作 $0\ dBr$ (指dB reference,dB参考系统)。专业音频设备中,$0\ dBr$ 相当于1.23V电压,音序器软件中,$0\ dBr$ 表示采样值大小为1。$0\ dBr$ 意味着系统电平上限,因此系统中绝大部分电平为负值。
$\diamondsuit$ 声音强度与几何衰减 平方反比定律
声音强度——Sound Intensity 记作 $I$ —— 是单位面积上的功率,单位:$W/m^2$,它正比于声压级SPL的平方($I \propto P^2$)。
声强级SIL和声压级一样,是一种比率,以分贝为单位,它的参考值是听阈声强 $I_0=10^{-12} W/m^2$ (可以被听到的最轻微的1000Hz纯音,其声音强度约为这一数值)。声强级的计算公式:$SIL=10\log_{10}\frac{I}{I_0}(dB) $
当一个点声源在理想空间里全方向辐射声波(形成无数层球面波)时,这个声音的能量均匀向外传播,能量被扩散、分配至每一个球面上,如球半径记作r,球面积为 $4\pi r^2$ 。因为声强被定义为单位面积上的功率(功率是声音每秒所发出的能量),所以声强可以表示为 $I=\frac{I_{source}}{4\pi r^2} $。
离声源越远的球面,半径越大,声强越小,且反比于半径(即距离)的平方,这就是平方反比定律。也可以说,功率的耗散正比于距离的平方。
这个比率关系可以表示为 $\frac{I_2}{I_1}=\frac{R_1 ^{\ 2}}{R_2 ^{\ 2}} $ ,$r$ 表示任意某个位置与点声源之间的距离,$I$ 即与其角标相对应的那个位置的声强。
因此可以计算,当听者处于距离点声源不同远近的位置时,声音强度的变化。如,从距离2米,变化到距离4米,$\frac{I_2}{I_1}=\frac{2^2}{4^2}=\frac{1}{4} $ ,也就是说,距离翻倍时,声音强度减弱为原来的1/4。由此,利用声强级公式即可算出两个声强级SIL的差值:
$$ 10\log_{10} \frac{I_1}{I_0}-10\log_{10} \frac{I_2}{I_0}=10\log_{10} \frac{I_1}{I_2}=10\log_{10}4 \approx 6\ dB\ SIL $$
这一规律经常被表述为“距离每翻一倍,音量降低6dB”。
Example
距离点声源的位置从10m变化到100m,音量降低多少?
根据平方反比定律可知,声音的强度之比为 $\frac{10^2}{100^2}=\frac{1}{100}$ ,计算声强级变化:$10\log_{10} 100=20\ dB$,音量损耗掉20 dB。
$\diamondsuit$ 声音叠加后的音量变化
从能量的角度来说,两个相同声音叠加,声能必然加倍,声强变为原来的2倍。但并不意味着分贝数翻倍,分贝本身就不是绝对量度,而是对数比率,它体现的是人耳对“变化”的“反应”规律。
计算分贝的变化,需要先返回到绝对量度的计算,然后再将结果转换到分贝。
$$ SIL_2-SIL_1=10\lg\frac{I_2}{I_0}-10\lg\frac{I_1}{I_0}=10\lg\frac{I_2}{I_1}=10\lg2 \approx 3.01 $$
叠加后到声音比原来的一个声音高出3分贝。 (这一增长规律基本不受频率和原声音强度的影响。)
如果两个声音频率一样但音量不同,同样可以利用上述方式计算,这时可能要先从分贝算回对应的原始声强的绝对测量值,再计算声强级的变化。
【绝对声强与声强级对照表】
| intensity($W/m^2$) | SIL(dB) |
|---|---|
| $10^{-2}$ | 100 |
| $10^{-3}$ | 90 |
| $10^{-4}$ | 80 |
| $10^{-5}$ | 70 |
| $10^{-6}$ | 60 |
| $10^{-7}$ | 50 |
| $10^{-8}$ | 40 |
| $10^{-9}$ | 30 |
| $10^{-10}$ | 20 |
| $10^{-11}$ | 10 |
| $10^{-12}$ | 0 |
【相对声强与增加分贝对照表】
| relative I | SIL (dB) |
|---|---|
| 1.00 | 0 |
| 1.26 | 1 |
| 1.58 | 2 |
| 2.00 | 3 |
| 2.51 | 4 |
| 3.16 | 5 |
| 3.98 | 6 |
| 5.01 | 7 |
| 6.31 | 8 |
| 7.94 | 9 |
| 10.00 | 10 |
利用表格和前面的SIL差值计算式,可以快速算出,两个叠加声音后的总和音量相比原声音的“增量”。
如果两个声音的音量不同,但差别不超6dB,叠加后的音量相比声音较大的那个,将增加约1dB。
如果两个声音的音量不同,但差别大于6dB,叠加后的音量相比声音较大的那个,差别很小,而且随着二者音量差的变大,总和音量相比较响者的“增量”会越来越小,所以可以大致的总结为,总和音量等同于音量较高者。
【 假设刚好6dB差别,从表中可知,二者的音强大约为4倍的关系。假设声音较小者的强度为 $I_1$,那么较大者就是 $4I_1$,总和声强级与声音较响者的声强级之差为:$10\lg\frac{1+4}{4} \approx 0.97\ dB$ ;如果相差7dB,根据上表,二者声强差不多刚好5倍关系,那么这一分贝差值为:$10\lg\frac{1+5}{5} \approx 0.79\ dB$ ;如果相差10dB,这一计算结果为:$10\lg\frac{1+10}{10} \approx 0.4\ dB$ 。所以这一数学规律已经很明显了,随着二者音量差别的增大,总和音量与较响者的声强级之差将会越来越小,从6dB差开始,就已经小于1了,,之后不断趋近零。人耳对音量变化的感知,至少要有1分贝差别。所以最终的音量可以近似认为就是较响者的音量。】
综上,
两个完全一样的声音叠加后,总和音量增加3dB;
两个频率一致、音量相差不超过6dB的声音叠加后,总和音量比较响者增加1dB;
两个频率一致、音量相差大于6dB的声音叠加后,总和音量等同于较响者。
- 声源类型
三种声源体:点、线、面。
理想状态下,一般将声源视为一个点声源,其声波辐射是全方向的。如果声源是一个长方形,长、宽分别为a、b,它形成了一个“面”。听者距离这个面的远近不同(记作r),对声源模型也可看作不同的形态。
- 如果r小于a、小于b,这是完全面声源的情况,声源的大表面震动层会产生复杂的声波区;
- 如果r大于a、大于b,这种情况将其视为点声源;
- 如果r大于a、b的某一边,小于另一边,这种情况将其视为“线声源”。
$\diamondsuit$ 障碍物与降噪
什么样的障碍物会阻止或显著降低声音?
影响声音的传播和衰减的障碍物特征:
密度:密度较高的障碍物(如墙壁、楼板)通常能够有效地阻止声音的传播,因为它们能吸收和散射声波。
厚度:厚度较大的障碍物对声音的阻挡效果更好。例如,厚实的墙壁比薄板更能降低声音传播。
质地:不同质地的障碍物对声音的衰减效果也有所不同。柔软材料(如织物、海绵)对声音具有吸收作用,而坚硬表面(如金属)则可能产生反射和回声。
孔洞或开口:存在孔洞或开口的障碍物(如门、窗户)会允许部分声音穿过,但通过孔洞或开口的声音会发生衰减。
障碍物高度:高度远小于声音波长时,障碍物影响相对较小。当障碍物的高度接近或大于声音波长时,障碍物会开始对声音产生明显的影响。高频声音(具有较小波长)更容易受到障碍物的影响。当障碍物的高度接近声音波长的2倍时,声音会发生明显的衍射现象,声波会绕过障碍物并沿着不同的方向传播。
实际生活中的一些经验:
障碍物通常对高频削弱力更大;声源应尽量远离具有反射效应的界面;声障效应一般在室外更典型;衍射引起的衰减通常不大于20dB;马路上的植物带有较好的隔离作用,200英尺的植物带对声源衰减最大达10dB;障碍物上方的植物也可起到隔离作用,主要是将声音散射出去。
- 界面
声波是种能量,显然不能令其消失,但可以改变它的传播方向或形式。
当声波遇到障碍物,通常会发生三种改变声能传播的进程:反射、传导、吸收。
固体界面通常会发射绝大部分声能,那些小部分未被反射的,有的被传导到外面了,剩下的被吸收到材料本身中。这一吸收过程实际上是将声能转化成了热能。这一过程就是摩擦吸声,硬质墙面通常起不到多少这样的作用。
- 隔声与隔音材料
隔声的目标就是使传导出去的声音远小于目标区域内的背景声。
隔音材料就是将声音的传达最小化,这意味着将反射或吸收最大化。
隔音墙的体积是隔音的决定性因素,坚硬度也很重要,对低频声波的传导有抑制作用。同时,还要考虑共振效应。
好的隔音要降低隔离物的坚硬度,并使用有吸声力的材料。实际场景中,一般采用双层墙面,中间塞轻质的吸声材料。每一层界面都会发射声波,因此减弱了声音的传导。中间材料用于降低空气共振,不然,两面墙之间会出现特定频率的共振(驻波效应)。
反射波会遇到以相反方向传播的其他的波阵面,并与它们发生干涉。两个波是相互加强还是抵消取决于它们的相对相位和频率。如果具有正确频率的波在一个物体的两个面之间反弹,并且该波的波长或波长的整数倍恰好等于反射之间的距离,那么就会产生驻波 standing wave。对于一个驻波来说,最好把它看成两个以相反方向运行的波来看待,两个波的密部和疏部彼此相互加强。驻波取决于振动物体的几何形状。物体某些特定长度会促进波在某些特定频率出现,并且会涌现出共振/谐振(resonance)或振动模态(mode)。因为大多数的实际物体都不是规则的,所以很多不同的频率会组合成一个复杂的动态过程。从一个物体中显露出来的声音振动的模式图样由这些共振构成,即在材料中弹来弹去的各个波。
- 隔振
建筑结构中的各类系统设备对静音室影响很大,声源体自身的振动也引起不必要的噪声。
常用的隔振手段:
控制和降低设备振动的噪音低蔓延;改善扬声器低频特性,减少低频谐振;在振动设备与建筑结构之间提供一层弹性材料。
-
三种基本吸声类型
摩擦吸声 曲面吸声 共鸣效应 原理 材料与空气分子摩擦 声能转换成热能 较薄的界面受声波冲击产生曲张 声能转化成热能 利用共振器原理吸声 应对 中高频 低频 各频段 材料 特点 海绵状多孔隙,增厚度可提高低频吸收 与墙壁隔开并填充松软绒状物可抑制低频 纺织物更针对高频 薄、软、有韧性的材料 专门的共振吸声器 对环境要求苛刻
- 回声 echo
35ms以下的延迟声会与原声音合在一起,听起来是一个声音。不过听者判断声源仍是以最先抵达的那部分声音的方向为准。这一现象称为Precedence effect 领先效应(也称哈斯效应)。
当延迟超过50ms,就会被听成两个声音了,后面出现的声音就被称为回声。
- 混响
混响是一种主要发生在封闭空间,如房间内的声学现象。
假设一个点声源,以球形波阵面全方向传播,声源发出的声音首先以直线传播到听音者(直达声),随后,由墙面、地板、天花板等所反射回来的声音陆续到达。之后是由很多界面的多次反射所形成的更加密集的反射声。由于声音在空气中的传播以及界面材料的吸收都会造成声音能量的衰减,因此反射声的振幅逐渐减小。
混响就是对房间界面的各种反射形成的所有声音的统称。
- 混响时间 $T_{60}$
混响时间测的是声音强度下落到初始强度以下60dB所花费的时间,因此记作 $T_{60}$。它的公式称为赛宾公式:
$$\text{Sabine Formula:} \ \ T_{60}=\frac{kV}{Aa},\ \ \text{赛宾常数k=0.16} $$
其中,V是房间容积($m^3$),A是房间总面积($m^2$)。a为吸声系数,由吸收引起的任何耗散都可用吸声系数来描述,它的值介于0~1之间,1意味着100%吸收,0意味着完美反射。
赛宾公式的另一种简易写法是:$T_{60}=0.16\frac{V}{S}$ ,S代表所有吸声面的总和,$S=S_1a_1+S_2a_2+...$
$\diamondsuit$ 回声与混响有着根本区别
当一个具体方向来的声音与反射回来的声音不连续的时候,就出现了回声。感觉上是对一个声音的重复。
混响没有方向性,没有声音的单独重复,计算的混响时间相当于表现整体音量和空间反射率的衰减速度。
名词与概念 - 心理声学
$\diamondsuit$ 频率分辨, 拍频现象与临界频带
拍频现象,也称差频、差拍,由两个频率非常接近的声波同时发声并送入人耳时发生,听觉感知到声
音振幅的周期性的起伏,类似颤音效果。这是因为两个声音叠加后的声波周期性地发生相位反转。
当两个声波(频率分别记作 $f_1,f_2$ ,二者的频率差记作 $f_{BF}$ )经过耳蜗,如果 $f_{BF}$ 足够大,耳蜗内基底膜上两个不同的区域便会响应相对应的频率,由此人便听到两个不同的声音。耳蜗这种将复杂音解析为原始的一组纯音的能力叫做频率分辨 frequency discrimination。
若要能够分辨出独立的两个音,它们的频率差 $f_{BF}$ 需要超过一个限度 —— 频率分辨极限 limit of frequency discrimination,记作 $\Delta f_{FD}$ 。
如果$f_{BF}$小于某个值,这两个声音所刺激的基底膜上的两个共振区域发生局部重叠,人耳感知到的就是一个声音,且有拍频现象。拍频出现的频次就是 $f_{BF}$ ,人耳感知的这“一个声音”的音高频率为二者的平均值 $f_{AF}=(f_1+f_2)/2 $ 。
一般而言,在常见的声音频带,差频达到约10~15Hz后,拍频现象会消失,随之而来的是一种声音的“粗糙感”。
当$f_{BF}$大于频率分辨的阈限 $\Delta f_{FD}$ 后,人耳开始感知到两个频率分别为$f_1,f_2$的声音,基底膜的两个区域被激活,共振区勉强不重叠了。这一阶段,声音的“糙感”还在,尤其是低频音会更明显。
当差频进一步增大,并终于超过一个称为临界频带 critical band 的界限时(记作 $\Delta f_{CB}$ ,粗糙的声音开始逐渐平衡清晰,人耳听到越来越明确的两个声音。
- 临界频带
这个概念,可以简单理解为人耳频率分辨能力的临界频率带宽。
临界频带(Critical Band)是指人耳在听觉上对于频率的分辨能力有限的一种现象。它表示了在听觉范围内,人耳对不同频率音调的感知并非完全独立,而是存在一定程度的相互干扰。
临界频带可以被定义为在听觉中心频率周围一定范围内的频率区域,在这个区域内的音调被认为在听觉上彼此相互影响。这意味着如果两个音调位于同一个临界频带内,则它们可能会相互干扰,难以被区分开来。
- 响度
响度是对声音强度的主观反应,人感知到的声音的响度与声音本身的强度、频率等很多因素有关。
- 响度单位-宋 sone
1宋定义为1kHz正弦波在40dB声压级的响度。这是个早期概念,现已基本被“方”而不再使用。
$\diamondsuit$ 等响曲线与响度单位-方 phon
通过大量实验得出的等响曲线描绘了人耳对频率和声压级的响度感知。等响曲线以1kHz作为参考频率。在声压的物理量度与主观听感对响度的判断之间,引入了“方”的概念,用以表示响度级的相对量度。1方被定义为声压级为1dB SPL的1kHz纯音的响度。
在等响曲线上,某方表示某一条曲线(或者说,一组数据点),这条曲线覆盖的所有频率的“方”都是一致的(听起来是一样响的)。
理论上,在同一级响度曲线上(某一条方曲线上)有无数个等效的声压-频率值。
同样的响度在不同频率段对应的声压级可能会有很大差异。1000Hz左右,曲线相对平稳;高频和低频区域曲线变化都很明显,若要获得同样响的声音,往往需要更高的声压级。
人耳对3~5kHz的声音最敏感,最容易听到。
在低频区域,声音响度较低时,人耳对低频的灵敏度下降最为明显。
响度有很多影响因素,除了声音自身的强度(声压级),频率、持续时间、起音长度等都会影响响度感知。
一个脉冲状的极短的声音,响度小于电平恒定的声音;时值对于响度的影响,在宽频噪音上更明显;混响会增加总体的声能,也会增加声音的时值,从而增加响度。
$\diamondsuit$ 声音定位
一对耳朵能够使我们根据被感知信号之间的差异来定位声源。一般规律:
具有尖锐起音的高频声音相对更容易定位;
起音瞬间最初的几毫秒最容易定位;
户外自由空间比在有大量反射的室内空间更容易定位声音;
通过移动头部改变方位角和仰角可以更好的定位声音。
- 耳间强度差
抵达两只耳朵的相对幅度,即立体声系统中的声像定位panning。简而言之,哪边耳朵听起来声音比较响,声源便可能来自哪个方向。
- 耳间时间差
同一个声音抵达两只耳朵的时间点差值。先抵达哪只耳朵,人耳就会判断声源可能来自哪个方向。
- 掩蔽效应
在时间上相邻或频谱上相邻的不相关声音可以互相干扰,有时一个声音会完全淹没另外一个声音,以至于那那个声音不再被听到。掩蔽现象有很多种情况,比如同时遮蔽、时域相邻遮蔽、临界频带遮蔽等。
遮蔽效应的常见规律:
频率相近的声音相互间遮掩作用更大。
低频遮蔽效应更高。
增加某个声音的强度,可以大大增加其遮掩能力。
窄频段噪声的遮掩能力和一个纯音差不多。
在一系列噪声中较为简单、纯粹的声音仍然很明显,即使音量比较低。
- 声学条件反射保护机制
人类听觉系统中的保护机制,免于受到过强的声音能量的冲击与伤害,一般规律是:
保护机制一般在声音超过85分贝时启动。
触发后,有30到40毫秒的反应时间
对于过于短促的声音,或起音极快的声音保护机制难以起作用。
这一机制会持续数分钟。
- 多普勒效应
当声源与听者之间有相对运动时,听者感受到表观频率上移或下移的变化现象。
当声源、介质和听者都相对静止时,耳鼓膜的震动与声源振动一致。但当声源和听者相对运动,并靠近时,人耳单位时间内接收到的声波密度增加,导致鼓膜振动频率高于声源本身的频率,于是感受到音调变高。反之就会感受到音调变低。
- 音色
音色和音质是对声音的主观感知和评价,由其振动类型、谐波状态等一系列因素决定。控制谐波状态、包络等,可控制声音的音质音色特征。
音色:一般指色彩表现、情绪化表现力,常描述为“很亮或很暗”。
音质:一般指对声音内在特征的主观认识,所指内容更宽泛、模糊。更多指代声音的构成材料与质地。
问题集 1
1,物理上描述声音的两个最基本特征是什么?
频率、振幅。
2,判断:任何一个自然产生的声音都可以认为是一个正弦波和它的谐波组成的。
错。自然声音确实可以解析为许多不同频率、振幅、相位的正弦波,但正弦波与其谐波构成的是周期性的声音。傅里叶理论解释了任何周期波都可以分解为一个基频波与它的一系列谐波。一个自然声音可能是有明确音高的声音,也可能是非周期性的噪音声波。
3,判断:自然声音的传播和水波纹一样是呈平面状的。
错。声波以球面圈向外扩散,理想状态下,一个点声源会在全方向上传播。
4,判断:声波是横向波动并向外辐射状扩散的。
错。声波是一种纵波,振动方向与传播方向一致,并不一定是横向传播。其扩散确实是辐射状、全方向扩散的。
5,回声是如何产生的?
声音的多次反射形成了回声。典型的山谷回声是由于复杂的山体表面和有较多对流的云层对声音造成多次随机的反射,且每次反射后声能会衰减一部分(被反射体吸收)。空旷宽广的山谷环境使声音有较远的传播距离,反射声需要经过略长的时间才能传回来。
很多个反射声有一定间隔的依次进入人耳,因此人们听到反复多次的“回响”,且音量逐渐降低直至消失。
6,判断:只有频率和振幅完全相同的两个声音才可能产生共振。
错。两个发声体的固有频率为整数倍关系时就会发生共振。
7,判断:两个频率、振幅完全相同的声音如果以180度相位差重合,就能相互抵消,从而产生的音量为零。
对。两个信号有180度相位差时,正负两极刚好抵消,振幅为零。
8,判断:不同材料对声能的衰减是一样的。
错。每种材质都有其特有的吸声率,会对声能造成不同程度的衰减。
9,判断:两个相同的声音同时发出时,总声能增加一倍。
对。从能量角度来说,两个相同声音叠加到一起,声音的能量必然加倍。
10,判断:如果两个声音电平相差在6dB内,那么增加部分的总电平只有1dB。
不一定。两个频率一致的声音,当电平差不超过6dB时,二者叠加后的总电平相比音量较大者会增加1dB。
11,判断:距离每增加一倍,音量就衰减6dB。
对。根据平方反比定律,声音强度之比为距离平方之反比。由此可以计算出二者声强级之差为6dB。
12,为何我们常见设备或软件都采用以0dB为上限的负数?
0dB作为一个参考标准代表了声音信号“原始音量”。某种意义上说,0的含义近似于"no cut and no boost",在增益上无削波、无衰减。我们平常使用的音量旋钮或音量控制器,本质上相当于一个衰减器,用于降低声音信号的输出。0dB便作为“最大音量”,当然在很大音响设备上也会看到少量0以上的正值区域,称为headroom,在不失真的情况下,可对声音信号做进一步的放大输出。
常见设备或软件采用以0dB为上限的负数的原因是为了避免信号过载和失真。
在音频领域,0dB通常表示一个参考电平,即被定义为最大可接受的信号强度。当信号超过0dB时,它将达到或超过设备或系统的最大处理能力,可能导致信号失真、削波或其他不良效果。
使用负数来表示信号强度的方式可以提供一定的安全余量。例如,常见的音频设备和软件中,通常将-20dBFS(Full Scale)作为标准参考电平,这意味着0dBFS表示最大可接受信号的强度,而更高于该值的信号会被视为过载。
采用负数的标尺还有助于保持动态范围。动态范围指的是系统能够处理的信号幅度范围。通过将0dB作为上限,可以确保较小幅度的信号仍然有足够的空间留给更大幅度的信号,从而保持音频质量和细节。
此外,在数字音频中,负数表示采样值(如PCM编码中),其中0表示零位值,并且负数表示在零位值以下的振幅。因此,在这种表示方式下,负数是自然的选择。
综上所述,常见设备和软件采用以0dB为上限的负数是为了避免信号过载、保持动态范围,并与数字音频编码方式相符合。
以下为心理声学部分的问题集
问题集 2
1,判断:发自点声源、线声源、面声源的声音随距离变化的衰减率是不同的。
对。
2,混响是如何定义的?
混响是一种发生在封闭空间内的声学现象,即声源停止发声后,声音继续延续的现象。
对混响的计算或者说“数值定义”指的是声音强度下落到初始强度以下60dB所花费的时间,一般记作 $T_{60}$。
3,噪声在理论上的定义
在理论上,噪音可以被定义为一种随机、不规则的信号或声波。它通常包含各种频率和振幅的成分,并且没有明确的周期性或可预测的模式。
4,简述一个物理存在的声音如何被人“听”到
声音产生时,发声体振动并对空气施加压力。这些压力变化通过耳道传入中耳,使鼓膜振动。鼓膜与中耳内的听小骨相连,将机械振动传送到内耳的液体中。
声能随后通过液体振动传导到敏感的耳蜗内。耳蜗内充满了微小的毛细胞,它们受到声能的振动刺激,并将其转化为神经信号,发送给大脑的听觉系统。最终,大脑做出反应的那部分便是人“听”到的内容。
5,人耳是如何判断声音位置的?
(一)双耳效应
双耳定向是双耳听觉中判断声源位置的特性。声场中的声源发出的声波到达两耳的路程不同,引起耳间时间差、耳间强度差以及频率差。这种差异使人耳判断先到达的或者声响较大的那个声音所在的方向为声源方向。如果声音抵达两耳的时间强度完全一致,人耳会判断声源在正前方。另外,头部本身的结构会对不同波长的声波造成不同程度的遮挡,从而使两耳接收到的声音会有强度差和音色差(形成声学阴影)。
(二)哈斯效应
哈斯效应也称延迟效应,它表征了人耳对延时声的分辨能力。两个同样的声音先后到达,若其中一个比另一个先到达5-35毫秒,人耳几乎不能察觉迟到的声音。后一个声音只起到丰满补充的作用。如果先后到达的时间差在30-50毫秒之间,人耳会有一点察觉,但仍然取决于先到达的那个声音的方向。只有时间差在50毫秒以上时,才有可能清楚分辨两个声音来自各自的方向。
6,什么是多普勒效应?
当听者与声源之间有相对运动时,随着距离接近声调,似乎变高了。反之,随着距离拉远,升调听起来似乎降低了。这种现象称为多普勒效应。
当声源、介质、听者都相对静止时,人耳鼓膜受到的振动与声源振动一致,但当声源与听者有相对运动并接近时,人耳在单位时间内接收到的声波密度增加,导致鼓膜振动频率高于声源振动频率,因此听起来音调升高。反之当距离拉远时受到的声波密度降低,鼓膜振动降低,因此音调听起来变低了。
7,遮掩效应只产生于一个较响的声音和一个较弱的声音之间吗?
一个声音的存在会影响人们对另一个声音的听觉能力。这种现象称为掩蔽效应,即一个声音在听觉上掩盖了另一个声音。
掩蔽值规定为,由于掩蔽声的存在,被掩蔽声的闻阈必须提高的分贝数。
掩蔽效应不仅与音量有关,它是一个复杂的生理和心理现象,与两个声音的声强及频率相对方向和持续时间等因素有关。
8,判断:人的听觉定位现象是产生立体声听觉印象的关键,因此听觉的空间感就与听觉的定位有最直接的关系。
对。人耳正是基于双耳间信号的时间、强度、频谱等差异对声音位置进行判断,如耳间强度差便体现了最基本的立体声定位方式,人耳对左右前后进行基本的方位判断,因此产生了听觉的空间感。
9,判断:声音的电平与响度成对等关系。
错。响度是人耳对声音物理强度的主观反应,听起来一样响的声音可能包含无数不同的声压级。响度与声压-频率值的关系被总结成等响曲线,每条曲线上的频率-声压都拥有同样的响度。
在不同的频段人耳对声音强度的反应有不同的规律,其中3-5kHz左右的区间是人耳最敏感的频段,较小的声压级听起来也会相对比较响,而在低频和高频区敏感度会明显下降。
10,任何一个自然产生的声音,其产生过程是哪四个阶段?
起音 衰减 保持 释放,也就是声音的包络,它是一个声音最基本的表现状态,也是影响音质的因素之一。
11,听觉的音乐性包含哪些基本特征?
节拍:对有规律的振幅波动的感知。
音高:由基频决定,但是非常主观的判断,音色音质也会影响对音高的感知。
时值:声音长度会影响对响度的感受极端的声音听起来较轻。
音色音质:声音色彩、波形轮廓。
律制、音调:基于频率形成的定音标准、律制标准以及调性色彩。
第三章 数字音频
名词与概念
-
ADC
模拟-数字转化,ADC的基本方法称为“脉冲编码调制” Pulse Code Modulation,这一过程分为三个步骤:采样、量化、编码。 -
采样 采样周期
采样就是每隔一个相同的时间间隔在模拟声音的波形上取一个幅度值,从而把时间上的连续信号变成离散信号的过程。这一时间间隔就是采样周期,其倒数为采样频率。(采样的过程也称脉冲振幅调制 PAM) -
采样点 samples
将模拟信号转换为数字信号这一过程中,通过ADC设备获取到的一个个离散数据(电压或数字流)。 -
采样率 sampling rate
将模拟信号进行采样的速率,即捕获样点的速度,可理解为每秒钟采集的声音样本的个数。采样率越高(采样的间隔时间越短),单位时间内得到的声音样本数量就越多,对声音波形的表示越精确。数值上,采样周期与采样率互为倒数。 -
采样定理 奈奎斯特理论
定理指出,当采样率大于等于被采信号最高频率的两倍时,就可以通过在采样值上进行插补的方法,得到原始信号的波形。即,采样后的数字信号能够完整保留原模拟信号的信息。
采样率的一半,称为“奈奎斯特频率”或“奈奎斯特点” Nyquist point。
【信号系统理论证明,对一个信号进行时域上的采样,等于在频域上以Nyquist point 及其倍频为镜子,进行镜像处理。】 -
频谱混叠 aliasing
如果采样率低于被采信号最高频的两倍,就会使得新增加的频谱成分有一部分与原信号的频谱相重叠,从而混杂在一起。这种频谱发生重叠的现象称为“频谱混叠”。之后再经过低通时,要么产生多余波形(cut off值为原信号最高频),要么少了很多波形以致变得比原来的波形曲线平滑(cut off 值避开aliasing 部分)。 -
采样定律成立条件
1,采样定理是在理想状态下得到的,实际运用时,采样前需经过低通控制被采信号的频率上限(抗混叠滤波器)。
2,恢复模拟信号时,使用理想的低通(通带全通,阻带全衰)。但理想低通实际不存在,通带、阻带之间总有一个过渡区,那么就不能选用刚好2倍的40kHz,必须要更高一点。 -
常用采样率
44.1 kHz:CD,MP3
48 kHz:DAT,伴随视频的音频
96 kHz:高质量录音,DVD - Audio 环绕声
192 kHz:目前最高 -
量化
将模拟信号的采样值以一定的单位进行度量,用数字记录和存储下来的过程。
具体而言,首先将采样后的信号按整个信号的幅度划分为有限个区段(量化阶数)的集合,然后把落入某个区段内的采样值归为一类,并赋予相同的量化值。
量化过程在数值上进行了一种四舍五入的整数化处理。
【如果说采样是从时间上将连续信号变为离散信号的过程,量化就是从幅度上将连续信号变为离散信号的过程。】 -
量化精度 量化阶数
某种量化精度下,能够表示出多少个数值,这个“数值个数”就是“阶数”。
每个量化值用几位比特的二进制码来表示,这个“精度”就是二进制“位数”。
“5位”就是用5 bit的二进制码,5位二进制最多能表示32个数,量化阶数就是32。
所以,n bit的精度,阶数就是 $2^n$ 个阶。 -
动态范围 dynamic range
通过采样得到的数字声音本质上是一串数字序列,每个数字都是采样到的离散的值(也意味着扬声器或耳机振膜的一个可能位置或“位移数据”),能够被表示的最高和最低数字设定了这个声音的动态范围。
扬声器只能移动到一定距离,否则将会被破坏。声卡和扬声器被设计成把位移限制在一个最大值以下的形式,这个最大值被称为满刻度偏转 full-scale deflection. -
数字编码 量化失真 quantisation distortion
数字编码的过程是将数据存储为二进制数,这意味着如果用n个二进制位来存储每个幅度值,则可以表示 $2^n$ 个值,于是二进制位数决定了可以表示的数值的量,那么,如果二进制位太少,就会引起量化失真,声音变得颗粒化、缺少细节(精度不够)。 -
量化精度 resolution
声音信号的每一个样点都以数字形式存储在计算机中,其数值表示的是每个信号被采样瞬间的幅度值。这些数字的范围需要足够大,足够充分去表达和记录被采样的音频的幅度范围。能够被表示的最高和最低数字决定了这个声音(采样后得到的数字声音)的“动态范围”。
但量化的精度是有限的,量化的值与原始信号的真实电压值总会有些偏移(quantization error),这是不可避免的,因此就会造成噪音的出。这种噪音并非原始信号中的,而是在量化过程中产生的、被加到数字信号中的,它便称为量化噪音 quantization noise。 -
SQNR 信噪比
信号整个的幅度范围与量化噪音之比。具体计算是最大可达到的信号幅度值比上量化噪音的平均等级,常用dB表示。一个经验所得的规律是,量化精度的每一位比特都会给SQNR增加6dB,所以8 bit位深的量化所得的声音信噪比就是48dB,CD标准质量(16 bit)的SQNR就是96dB。 -
DAC
数字-模拟 转换。这一过程的基本步骤:
1,解码,将数字音频信号的字(二进制数)转换为阶梯状电平链。
2,再采样,在时域中对采样信号进行插补,减少脉冲宽度,以减少孔径效应。
3,低通,通过LPF,将采样点连接成平滑的波形,重建出原始模拟信号。
$\diamondsuit$ 模拟 vs 数字
模拟音频信号,指的是用其他物体的运动来“模仿声音的波动所产生的信号(模拟电信号、扬声器纸盆的振动等)。最大特点:时间上的连续性,任何一个时间点上都存在一个与之对应的振幅值,因此它是一种渐变信号。
数字音频信号,一种时间轴上的离散信号,它仅在一定的时间点上存在振幅值,因此它是一种跳变信号。数字音频的优点:可进行无损复制,易于加工处理,数字设备成本低。
-
合成器
利用声音的基本属性(如正弦音和其他简单波形),以电子方式制作声音。最简单的合成器:正弦波发生器。 -
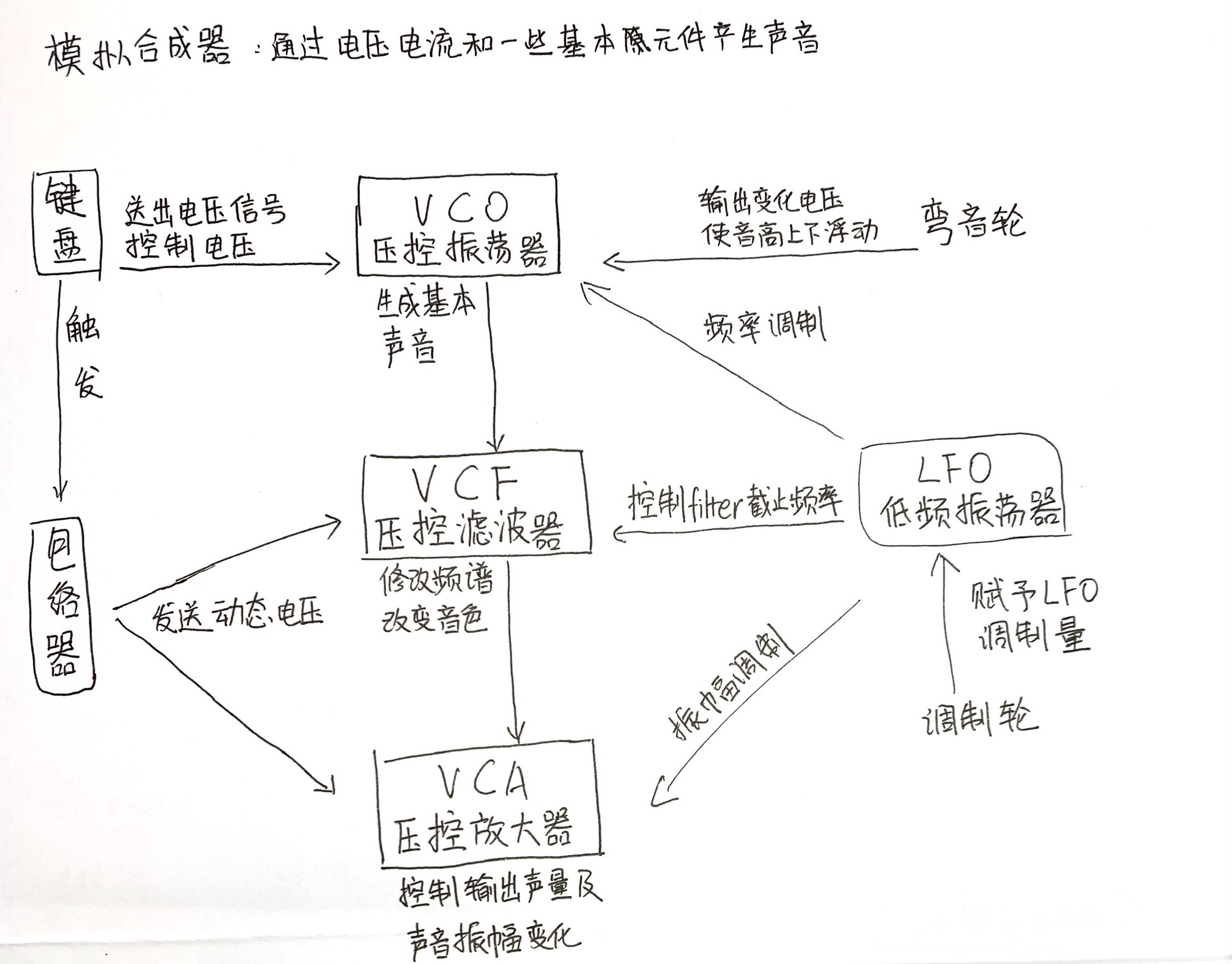
模拟合成器
结合电压控制电路来产生并形成声音。电压通常与波形音高直接相关,电压越高、音高越高。
基本构成:VCO,VCF,VCA- VCO 压控振荡器:产生疾病音色,音高由合成器键盘控制(通过控制电压)。
- VCF 压控滤波器:基本音色送入滤波器,获得各种谐波,形成音色特征。
- VCA 压控放大器:包络控制,给已形成的声音赋予一些表现力,同时放大声音信号。
-
振荡器产生的四种基本波形
- 正弦波:纯净、清晰明了,只有基音,单独使用可创造“纯净”的声音(口哨、音叉声)。
- 锯齿波:清晰明亮,包含奇数和偶数倍谐波,适于创造弦乐、铜管声音、背景音等。
- 方波和脉冲波:方波听起来空旷有木质感,包括多种奇数谐波。在创造簧乐器、背景音等声音时很有效。也可用于模拟底鼓、嗵嗵鼓等打击乐器声音,通常与其他波形混合。使用脉冲宽度调制可以重新调整方波形状,获得不同程度的脉冲波,它更接近簧片乐器声音,比较薄。
- 三角波:只包括奇数倍谐波,三角波中较高频的谐波振幅滚降得很快,因此听起来更柔和,适于创造长笛之类的声音。
-
白噪音 粉红噪音
白噪音包含所有频率,处于最大电平,随机性较大。
粉红噪音包含所有频率,但在频谱中不处于最高电平,高频每八度降低3dB(粉)或6dB(红)。 -
低通
滤除高频的过程是渐变的,频率越高的部分切除量越大,基本规范:每八度衰减12dB或24dB -
滤波器关键参数
- 截止频率:决定了滤波器从一个声音的哪个频率开始起作用。
- 共鸣量:加强或抑制截频周围的信号。非常高的共振设置会引起滤波器自振荡,从而使滤波器生成可闻的正弦波。也称Q值。
- 斜率:每八度衰减程度,如Logic Pro中的自动滤波器有4级:6,12,18,24 dB。
-
包络发生器
模拟合成器中,包络发生器本质上是在向VCA、VCF发送动态变化的电压,从而控制声音的外形轮廓。 -
起音 Attack
音头,声音起始并且音量上升的阶段,它描述一个声音以多快的速度上升到最高点。 -
衰减 Decay
声音上升到最高点后下降到稳定阶段的时间,它描述声音以多快的速度衰减到持续段音量。 -
保持 Sustain
声音维持相对稳定的阶段,声音在此阶段是相对有规律的状态,因此也是选取loop段落时寻找的位置。控制值为电平相对量,百分之多少,而非时间或速度。 -
释放 Release
释音阶段,描述了停止发声后,声音以多快的速度从保持阶段的音量开始下降直至消失。 -
LFO
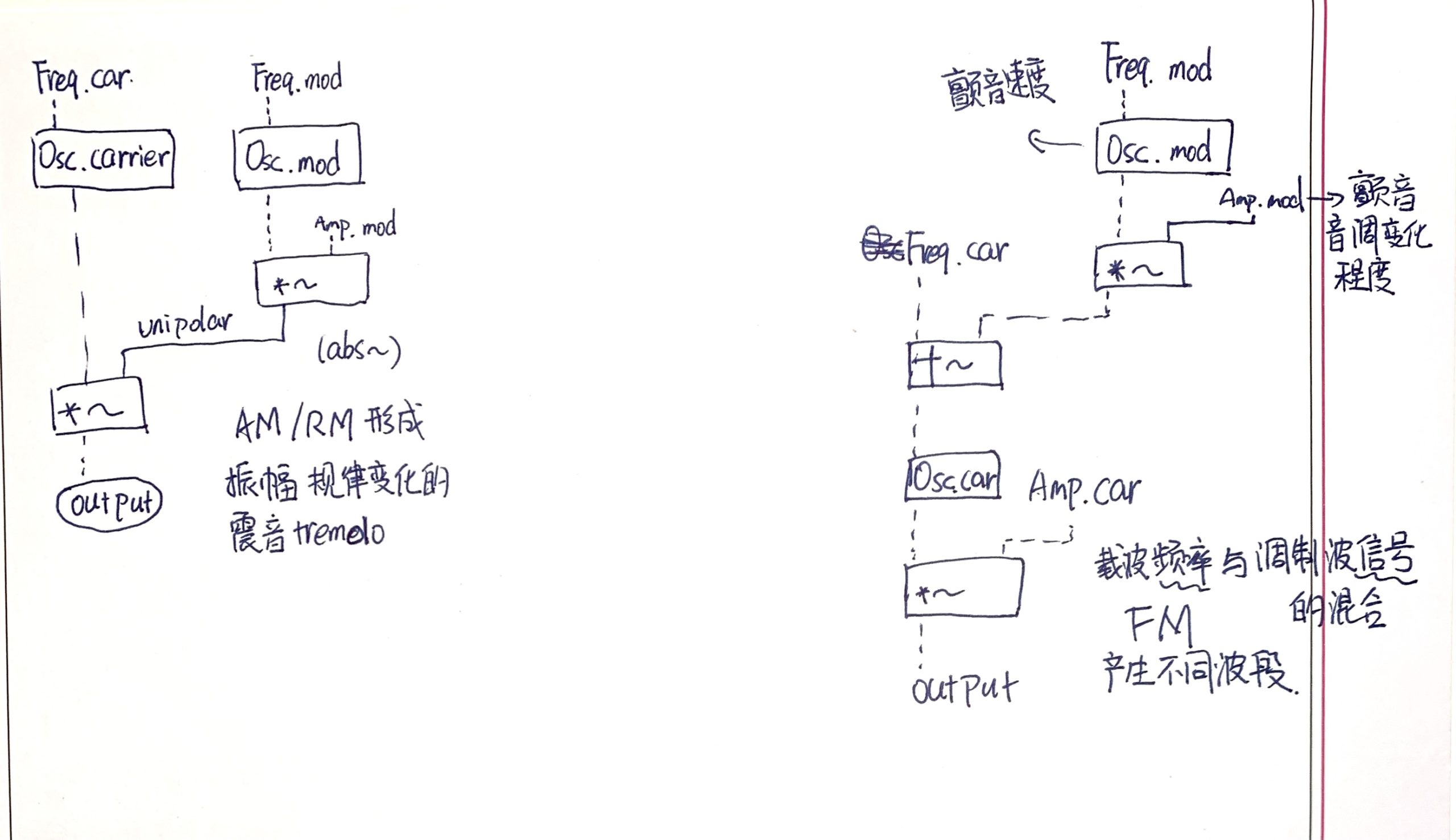
低频振动器,范围通常在 $ 1/60~10\ Hz$ ,常用正弦波和三角波。 -
调制 modulation
用一个声波介入和影响另一个声音的过程,一般称“调制”。 -
LFO对模拟合成器三个模块的调制
调制VCO,会产生vibrato —— 频率微调的颤音;
调制VCA,会产生tremolo —— 振幅微移的震音:
调制VCF,对filter的控制可以产生多种效果,如wobble bass、sweep等。
问题集
1,什么是量化?
将模拟信号的采样值,以一定的幅度单位进行度量并以数字记录的过程。
相比采样过程在时间上将连续信号变为离散信号,量化相当于在幅度上将连续信号变为离散信号。
2,什么是倍频原理?
即采样定理或奈奎斯特理论。定理指出,当采样率大于等于被采信号最高频的两倍时,才能得到接近原始信号的波形。采样率的一半称为奈奎斯特频率。
3,什么是采样率和采样深度?
将模拟信号进行采样的速率,即每秒采集的声音样本的个数,单位:赫兹。采样率越高,对声音波形的表示越准确。
采样深度,即量化深度,也称量化位数或比特深度,采样信号的量化值一般用二进制数来表示,这个二进制数的位数就是量化深度,它决定了量化阶数的多少,也就决定了量化值的精度,或称:数字分辨率。
4,判断:8比特,16比特,只是两种不同的数据编码方式而已。
错。比特位数指的不是编码方式而是量化精度。8比特位深的量化阶数只有 $2^8=256$ ,而16比特的量化阶数可达 $2^16=65536$ ,精度就高了许多。
5,什么是ADSR,和包络是否一样?
ADSR分贝意味着声音从出现到消失的四个表现阶段:Attack, Decay, Sustain, Release.
包络表示声音波形的外观轮廓,它并不完全等同于ADSR,虽然ADSR是对包络的基本表示方法,但包络是一个更大的概念。 实际的声音包络可能包含比ADSR更多或更少的阶段。
6,简述LFO的作用
Low Frequency Oscillator,低频振动器,本质上也是一个生成基本波形的振动器,但它专门用来产生不可闻的超低频。LFO生成波形不是用来听,而是用来调制其他波形。它的应用非常广泛,如在合成器中,各基本组件都可能用到LFO来调制。
除了在合成器中作为一个组件,LFO也常单独使用在电子音乐、声音设计等工作中。
7,分别解释VCO,VCF,VCA
VCO 电压控制振动器,产生基本信号,音高由电压控制,一般通过键盘控制器控制电压。电压越高、音高越高。VCO生成基本波形,如正弦波、锯齿波等。
VCF 电压控制滤波器,VCO产生的基本波形通过滤波器,为声音作出频率上的修改,形成更丰富的频谱变化,以改变音色。
VCA 电压控制放大器,对生成的声音进行振幅控制,形成特有的包络从而创造出独特的音色。并且,对最后的声音输出也进行整体的音量控制。
8,判断:ADPCM采用4比特编码,所以它是一种有损压缩。
错。Adaptive Differential Pulse code Modulation 自适应差分脉冲编码调制,是一种无损压缩方案,压缩率比较低。它在DPCM的基础上对不同的频段设置不同的量化精度。
ADPCM(自适应差分脉冲编码调制)是一种音频数据压缩和编码技术。它通过对音频信号的采样和编码来减少数据的存储和传输量,同时尽量保持音质。
ADPCM使用差分脉冲编码调制的原理来压缩音频数据。它首先将连续的音频信号转换为离散的采样值,并计算每个采样值与前一个采样值之间的差异。然后,根据这些差异值,选择最接近的预定义编码器状态,并将此状态作为编码的一部分传输或存储。
在解码端,接收到的编码数据被用于还原差异值,并结合前一个采样值来重建原始音频信号。通过使用自适应算法,ADPCM可以根据输入信号的动态范围和特性,动态地调整编码参数以优化音质和压缩效率。
9,判断:MP3采用一种固定压缩率的压缩格式
错。MP3标准压缩率是1/12,但可变,码率在32~384 kbps之间。
MP3(MPEG-1 Audio Layer 3)是一种广泛使用的音频压缩格式,它通过有损压缩算法实现高度的数据压缩,同时尽量保持良好的音质。
MP3采用了基于人听觉特性的压缩算法,能够显著减小音频文件的大小。典型的MP3文件可以将原始音频数据压缩到原来的10%左右,即仅需要原始文件大小的约1/10。
MP3的压缩率取决于所选的比特率。比特率表示每秒传输或存储的位数,用于衡量音频质量和文件大小之间的平衡。较低的比特率会导致更高的压缩率和较小的文件大小,但可能会牺牲音质;而较高的比特率则会提供更好的音质,但会增加文件大小。
通常情况下,128 kbps(千比特每秒)被认为是MP3中较为常见和广泛接受的比特率设置。在这个比特率下,MP3可以提供较好的音质和相对较小的文件大小。然而,MP3还支持其他比特率选项,使用户根据具体需求进行选择。
10,判断:32比特WAV文件,它的采样深度就是32比特。
不一定,对于32比特的WAV文件,它的文件格式支持使用32比特的采样深度来存储音频数据。这意味着每个采样点可以使用32比特来表示其振幅值。较高的采样深度可以提供更大的动态范围和更精确的音频表示。
但并不是所有32比特的WAV文件都会使用全部32比特来表示音频信号。实际上,很多音频录制设备和软件通常使用较低的位深度(如16或24比特)来捕捉和处理音频信号。当将这些音频数据保存为32比特WAV文件时,可能会使用零填充或其他方式将其扩展到32比特。因此,在具体情况下,32比特WAV文件的实际有效采样深度可以低于32比特。
第四章 音响的系统构成
名词与概念
-
传声器
话筒,也称传声器,本质上是一种换能器,把声能转换成电能 -
动圈话筒
基本原理:声波驱动振膜,振膜驱动与之相连的线圈在磁场中运动,变化的磁场产生变化的电压,从而获得与声压成正比的电压输出。
特点:灵敏度低,可承受高声压级,降低环境噪声输出,但需近距离拾音。结实、耐用。 -
电容话筒
基本原理:通过改变电路中电容器的电容量,使声压转换成电压输出。电容器的前极板为振膜,后极板是固定极板。两个极板之间有稳定电场。声波驱动前极板运动时,改变了两极板之间的距离,导致电容器两端输出电压的改变,从而获得与声压相对应的输出电压。
特点:需要48V幻象供电,灵敏度高,频响范围大,成本高。 -
铝带式话筒
基本原理:使用一片极薄的铝带悬置在电磁线圈中,受到声压振动后,铝带产生运动,进而切割磁力线产生感应电流。
特点:输出电压小,需使用高质量的前端放大器,对材料要求高,成本高。一般需要近距离拾音。比较适于铜管类乐器拾音。
$\diamondsuit$ 话筒基本指标
-
指向性 - 决定了话筒拾音的有效角度和范围。
A. 指向性话筒
a. 心形指向 - 拾取正前方,两边越来越弱,90度位置 -6dB,正后方反应最弱。
b. 超心形 - 拾取正前方,灵敏度高,90度位置 -9dB,180度位置 -12dB。能够拾取前方较远距离的声音,对两侧反应弱。
c. 亚心形 - 前方指向性不明显,接近前方全指向,90度位置 -3dB,180度位置 -10dB,适于古典音乐录音。
d. 特心形 - 对前方较远距离非常灵敏,而两侧几乎拾取不到,90度位置 -12dB,非常适合防止拾音声泄露问题,适于录鼓组。
e. 双指向 - 拾取话筒两侧,如放在两个乐器或两个电声乐器音箱之间。B. 非指向/全指向型话筒
拾取各方向的声音,因此适于拾取房间的环境效果,如录制整个弦乐声部或合唱声部。 -
灵敏度
指进入话筒的声压功率与话筒输出功率之间的比例关系。它代表传声器的“声电转换能力”。普通传声器灵敏度 -60 dBV左右,高灵敏度的专业传声器可达到 -40 dBV以上。 -
频率响应
指话筒灵敏度随频率变化的特性,如平直的频响能反应出声源自身的特性。 -
阻抗
电路中决定话筒灵敏度的主要因素。 -
信噪比
有效信号与噪声信号之间的比例,总的最大输出信号电平与话筒自身的稳定噪声电平的比率。 -
线材
线缆的长度、材料也会对阻抗和本底噪声产生影响。
常见话筒类型的例子及其相应的灵敏度范围:
动圈话筒(Dynamic Microphone):
灵敏度范围:-60 dBV/Pa 至 -50 dBV/Pa
例如:Shure SM58,灵敏度为-54.5 dBV/Pa
电容话筒(Condenser Microphone):灵敏度范围:-40 dBV/Pa 至 -30 dBV/Pa
例如:Neumann U87,灵敏度为-32 dBV/Pa
扩音器话筒(Lavalier Microphone):灵敏度范围:-50 dBV/Pa 至 -30 dBV/Pa
例如:Sennheiser ME2,灵敏度为-36 dBV/Pa以Shure SM58为例计算话筒灵敏度:
首先,需要了解所使用的参考电压值。在这种情况下,dBV单位表示参考电压为1V。
$$ 灵敏度(dB)= 20 \log{10}(V{out} / V{ref})$$
通过专业仪器测得话筒的输出电压是0.001412538V,就可以计算以分贝为单位的灵敏度:
$$20 \log{10}(0.001412538V / 1)\approx -54.5\ dBV $$
- 总线/母线 bus
调音台上的总线输出,在这条通路上,很多信号被混合在一起。它往往决定了调音台在物理上同时传输至外部的音频轨道数量。
在调音台中,"bus" 是指一组信号路径,它们可以将多个音频信号从一个地方路由到另一个地方。Bus 在调音台上起到两个主要的作用:
信号路由:Bus 允许你将多个音频信号合并成一个单独的信号,并将其发送到其他处理器、效果器或输出设备。
控制和处理:Bus 还提供了对一组信号的集中控制和处理功能。
在调音台上,通常会有多个不同类型的 bus。
- 主输出总线(Main Bus):主输出总线是调音台上最基本和最重要的总线。它将所有信号通道中的音频混合在一起,并将混合后的信号发送到主输出。主输出总线通常与主音量控制器关联,用于控制整个混音的总体音量。
辅助总线(Aux Bus):辅助总线用于创建并控制额外的音频信号路径,通常用于发送效果器、处理器或者监听系统。这些总线可以用来创建独立的效果混响、延迟等,并且可以通过辅助总线控制每个效果处理器的湿/干比例或者发送级别。
组总线(Group Bus):组总线类似于辅助总线,但其功能更为强大。组总线允许你将多个音频信道(例如鼓组、合唱团等)路由到一个单独的总线上,以便进行统一的处理和控制。你可以为每个组总线设置独立的音量、平衡、EQ 和其他处理参数,从而对整个组进行集中处理。
直通总线/点对点总线(Direct Out/Insert Bus):这种总线类型通常用于将单个信号通道的音频直接发送到外部设备,如录音机、压缩器或其他处理器。直通总线允许你从调音台中获取单独的信号通道输出,以便进行额外的处理或记录。
-
处理器 processor
改变输入信号,并用处理后的信号完全替代原输入信号的设备(或电路、软件编码),在信号通路中以串联方式连接。比如,均衡器、动态范围处理器(压缩、限制、噪声门、扩展、闪避处理器)、失真处理器、音调纠正处理器、推位衰减器、声像电位器。 -
效果器 effect
为原始信号增加新的内容。效果器接收输入信号,并根据这个原始信号生成新的信号。在信号通路中以并联方式连接。
Dry - 干信号,即未经处理的原始输入信号。
Wet - 湿信号,有效果器新生成的信号。
干湿信号在效果器内部混合在一起并输出。干湿比例通常由单一的百分比控制器来控制,也可以用两个电平分开控制。大部分效果器都是对时间进行处理的设备,比如混响器、延时器、合成效果器、镶边效果器。 -
平衡与非平衡连接
-
平衡连接:平衡连接使用三根导线(通常是XLR或TRS插头),分别为正极性信号线(+)、负极性信号线(-)和地线。这种连接方式通过将信号传递在两个相互对称的导线上,可以有效减少干扰和噪音的影响。在平衡连接中,信号的正极性通过正极性信号线传输,而负极性则通过负极性信号线传输。当接收设备收到信号时,它会通过比较两个信号线上的电压差异来提取原始音频信号,并消除其中的噪声和干扰。
-
非平衡连接:非平衡连接使用两根导线(通常是RCA或TS插头),分别为信号线和地线。这种连接方式只传输单个极性的音频信号,并且没有对抗干扰的措施。非平衡连接容易受到电磁干扰、电源干扰和其他环境因素的影响,可能导致音频质量下降或引入噪音。
-
-
Dolby Stereo
杜比立体声技术是由杜比实验室开发的一种音频处理技术,旨在提供更加逼真和沉浸式的音频体验。其基本原理是利用人耳的听觉特性和空间定位能力,以在多个扬声器上创造出具有深度、广度和高度感的立体声效果。这种技术可以使听众感受到音源在水平方向(左右)、垂直方向(上下)和深度方向(前后)的位置。
在杜比立体声系统中,音频信号会被编码成多个通道,每个通道代表不同的音频元素或方向。常见的杜比立体声格式包括杜比环绕(Dolby Surround)、杜比数字(Dolby Digital)和杜比全景声(Dolby Atmos)等。-
杜比环绕:杜比环绕是最早引入的杜比立体声技术之一。它使用额外的后置扬声器(通常为两个)来增强环绕声效果,使听众感受到来自周围环境的音频信息。
-
杜比数字:杜比数字是一种压缩编码格式,在电影院和家庭影院系统中广泛使用。它可以提供多个独立的音频通道,包括前置、后置和低音炮(LFE)通道,以实现更加逼真和动态的音效。
-
杜比全景声:杜比全景声是杜比最新的立体声技术,旨在创造出更加真实和沉浸式的音频体验。它利用对象导向的音频编码和渲染技术,可以将音源定位到三维空间中的任意位置,并在多个扬声器上进行精确呈现。
-
-
杜比定向逻辑环绕声系统 Dolby Pro Logic
Dolby Pro Logic技术基于4个主要的音频通道:前置左右(Front Left/Right)、中央(Center)和单声道环绕(Mono Surround)。
工作原理如下:-
编码:原始立体声信号(左右通道)被编码成一个包含额外环绕信息的两声道信号。编码过程根据音频内容将部分音频信息混合到中央通道和单声道环绕通道中。
-
传输:编码后的信号可以通过普通的双声道传输媒介(如模拟电缆或数字传输)进行传输,无需特殊设备或连接。
-
解码:接收端使用Dolby Pro Logic解码器对传输的两声道信号进行解码。解码器会从混合后的信号中还原出左右、中央和环绕通道的音频信息。
-
环绕声效果:通过将环绕通道的音频信号通过后置扬声器播放,Dolby Pro Logic技术可以为听众提供环绕声效果,在音源周围营造出更加逼真和立体的音频体验。
-
Dolby Pro Logic广泛应用于家庭影院系统、电视机和音乐播放器等设备中。它是一种成本效益高、易于实现且与现有立体声设备兼容的环绕声解决方案。虽然Dolby Pro Logic在技术上已经被更先进的环绕声格式所取代,但它仍然是许多旧版影片、音乐和游戏中使用的一种常见的环绕声技术。
-
效果器插件格式
常见的效果器插件格式包括以下几种:-
VST (Virtual Studio Technology): VST是一种广泛使用的音频效果器插件格式,由Steinberg开发。它允许第三方开发人员创建各种音频效果器和虚拟乐器,并在支持VST的音频工作站软件中使用。
-
AU (Audio Units): AU是苹果公司开发的音频插件标准,主要用于macOS上的音频应用程序。AU插件可用于各种音频处理任务,包括效果器和虚拟乐器。
-
AAX (Avid Audio eXtension): AAX是Avid公司为其Pro Tools音频工作站软件开发的插件格式。它支持不同平台(如Windows和Mac)上的混合和音频处理任务,并具有较低的延迟和更高的性能。
-
DirectX: DirectX是由微软公司开发的多媒体编程接口,其中包含了用于音频处理和效果器插件的DirectX插件格式。尽管DirectX插件在过去较为流行,但现在已逐渐被其他插件格式所取代。
-
RTAS (Real-Time AudioSuite): RTAS是Avid公司早期版本的Pro Tools所使用的插件格式。尽管RTAS在现代版本的Pro Tools中已经被AAX格式所取代,但仍然可以在一些旧版的Pro Tools项目中使用。
-
-
虚拟乐器
虚拟乐器是一种音频软件或插件,模拟并产生各种乐器的声音。它们通过数字信号处理和采样技术来模拟真实乐器的音色、演奏特性和表现力。
通常由以下几个组件组成:-
音色库(Sample Library):包含了录制或采样的真实乐器音色样本。这些样本经过高质量的录制,并按照不同音高和表演技巧进行采样,以尽可能真实地再现乐器的声音。
-
音色引擎(Sound Engine):用于处理和再现音色库中的采样数据。音色引擎可以应用不同的音频处理算法,如滤波、合成、音频效果等,以模拟乐器的声音特性和表现力。
-
MIDI(Musical Instrument Digital Interface)控制:虚拟乐器通常可以通过MIDI控制信号接收来模拟乐器演奏。MIDI信息包含了关于音高、强度、持续时间等方面的指令,虚拟乐器会根据这些指令生成相应的声音。
-
用户界面(User Interface):虚拟乐器通常会提供一个可视化界面,让用户进行参数调整、音色选择和其他控制操作。用户界面可以是一个独立的应用程序,也可以作为插件集成到音频工作站软件中。
-
$\diamondsuit$ 虚拟乐器 or 插件乐器
虚拟乐器通常是一种软件合成器,它可以模拟各种乐器的声音。虚拟乐器使用数字信号处理技术和采样库来产生乐器音色,并通过计算机软件进行控制和演奏。
插件乐器(插件音源)是指以插件形式集成到音频工作站软件中的乐器。这些插件乐器可以是虚拟乐器,也可以是其他类型的合成器或采样器。插件乐器提供了直接在音频工作站软件内部使用的便利性,用户可以在同一界面上进行音频录制、编辑和处理,并直接使用插件乐器进行创作和演奏。
因此,虚拟乐器可以是一种插件乐器,也可以独立存在为独立应用程序。虚拟乐器是更广泛的概念。
- 数字音频接口协议 Digital Audio Interface Protocal
行业协会标准:AES/EBU, MADI 等
厂商标准:S/PDIF, ADAT, TDIF 等
问题集
1,ASIO的全称
Audio Stream Input/Output, 音频数据流输入输出,是一种专业音频接口技术。
ASIO的主要优势在于低延迟。传统的音频驱动程序(如DirectSound)通常会引入较大的延迟,这对于需要实时响应的音频应用(如音乐制作和录音)可能会产生问题。ASIO通过直接访问音频硬件,绕过了操作系统的中间层,从而减少了延迟。
另一个ASIO的优势是它支持多通道音频输入和输出,并允许用户以较高的采样率和比特深度进行录制和播放。这使得ASIO非常适合专业音频工作站软件和硬件设备,可以处理复杂的多轨音频项目。
在使用ASIO时,用户通常需要安装相应的ASIO驱动程序,这些驱动程序与特定的音频接口或设备相关联。一旦安装了正确的驱动程序,用户可以将其选择为音频输入和输出设备,并通过支持ASIO的软件进行配置和控制。
2,当前主要的音频协议、标准。
目前主要的音频协议和标准包括以下几种:
-
Audio Stream Input/Output (ASIO): ASIO是一种音频接口技术,用于提供低延迟和高性能的音频输入和输出。它主要在专业音频领域使用。
-
Universal Audio Architecture (UAA) / High Definition Audio (HDA): UAA和HDA是微软开发的音频架构标准,旨在提供统一的音频接口和驱动程序模型。它们广泛用于个人电脑和笔记本电脑中。
-
Audio Engineering Society (AES)/EBU Digital Audio Interface: AES/EBU是一种数字音频接口标准,由Audio Engineering Society(AES)和欧洲广播联盟(EBU)共同制定。它定义了用于传输多声道数字音频信号的接口和协议。
-
MIDI (Musical Instrument Digital Interface): MIDI是一种通信协议,用于控制音乐设备、合成器和计算机之间的交互。它允许音符、控制消息和其他音乐指令通过MIDI连接进行传输。
-
Open Sound Control (OSC): OSC是一种网络音频控制协议,用于在计算机网络上发送实时音频数据和控制命令。它可用于实现分布式音频处理和控制系统。
-
Dante: Dante是一种以以太网为基础的音频网络协议,允许在IP网络上传输多声道音频信号。它被广泛应用于音频行业中的现场音频传输和网络音频系统。
这些是当前主要的音频协议和标准,每种标准都有不同的应用场景和特点,适用于不同的音频设备和应用需求。
3,支持GSIF 2 的软硬件有哪些?
GSIF(GigaStudio Interchange Format)是一种音频接口标准,由Tascam开发,用于连接和控制音频设备、软件和工作站。GSIF 2是GSIF的第二个版本,引入了更高的性能和功能。
以下是一些支持GSIF 2的软硬件:
-
GigaStudio: GigaStudio是一款采样音色库软件,支持GSIF 2接口。它可以与GSIF 2兼容的硬件设备进行连接,并提供高质量的采样音色和多音轨录制功能。
-
Tascam DM-24数字混音台:Tascam DM-24是一款数字混音台,具有GSIF 2兼容的音频接口。它可以与计算机连接,通过GSIF 2实现低延迟的音频输入和输出。
-
Creamware Scope DSP平台:Creamware Scope是一种DSP平台,可用于音频处理和合成。某些版本的Scope支持GSIF 2接口,使其成为一个强大的音频工作站解决方案。
GSIF在音频行业中已经逐渐被其他标准取代,如ASIO和其他专有接口。因此,目前支持GSIF 2的软硬件选择相对较少,并且更多的厂商和用户已经转向使用其他标准接口。
画图题目
AM与FM调制器基本结构
模拟合成器基本结构
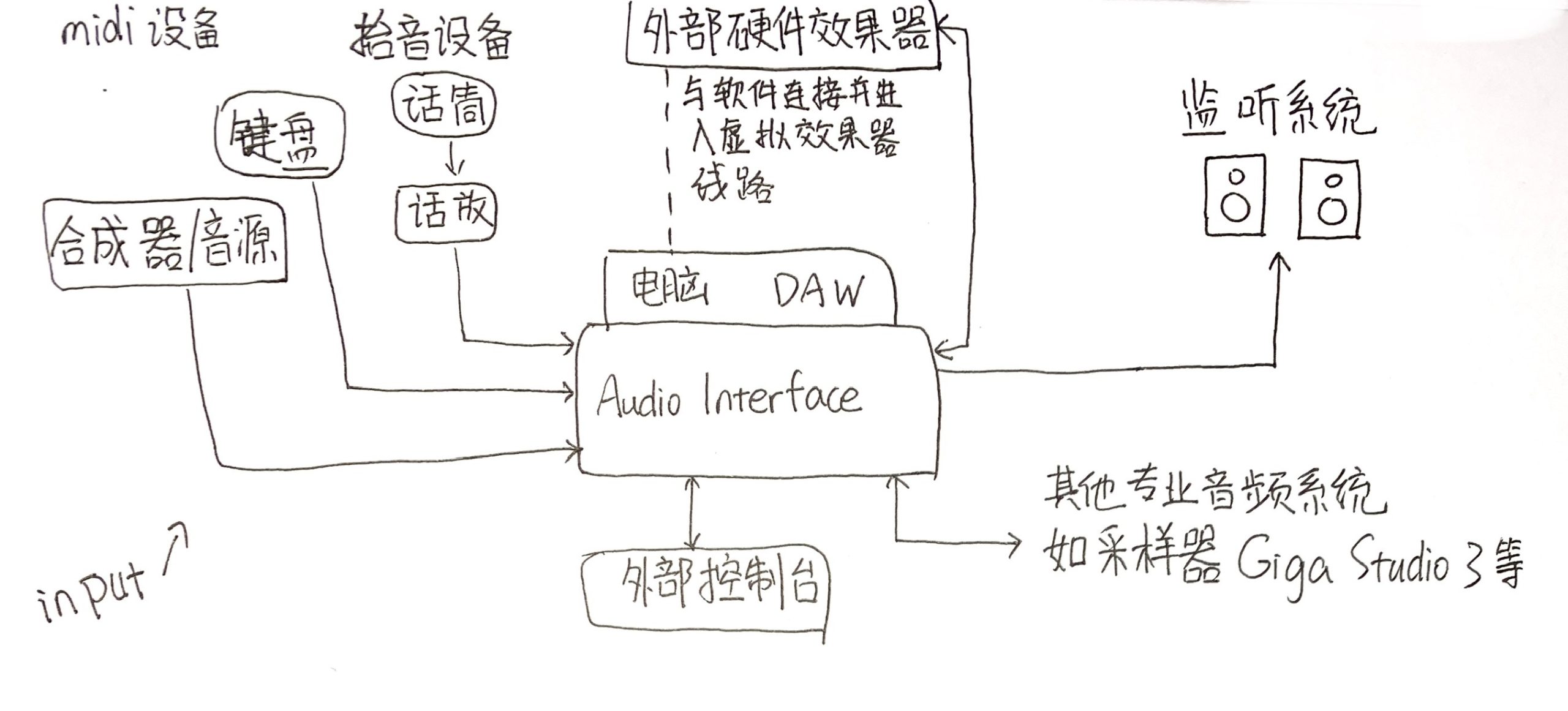
录音棚基本配置